
LD1
ld1指令可以从内存中load数据到一个或多个寄存器

when opcode == 0111.
LD1 { <Vt>.<T> }, [<Xn|SP>]
when opcode == 1010.
LD1 { <Vt>.<T>, <Vt2>.<T> }, [<Xn|SP>]
when opcode == 0110.
LD1 { <Vt>.<T>, <Vt2>.<T>, <Vt3>.<T> }, [<Xn|SP>]
when opcode == 0010.
LD1 { <Vt>.<T>, <Vt2>.<T>, <Vt3>.<T>, <Vt4>.<T> }, [<Xn|SP>]
T可以为以下值,设置T时还会指定size和Q位置的值:
- 8B when size = 00,Q = 0
- 16B when size = 00,Q = 1
- 4H when size = 01,Q = 0
- 8H when size = 01,Q = 1
- 2S when size = 10,Q = 0
- 4S when size = 10,Q = 1
- 1D when size = 11,Q = 0
- 2D when size = 11,Q = 1
<Xn|SP> Is the 64-bit name of the general-purpose base register or stack pointer, encoded in the “Rn” field.
EXT
EXT <Vd>.<T>, <Vn>.<T>, <Vm>.<T>, #<index>
这应该是指令的存储在寄存器上的格式(encode了所有所需要的信息)。

ext实现的功能应该类似于neon函数vextq_f32,就是将前后两个寄存器里存的值组合起来放到一个寄存器中,由最后一位index来指定,不过有点让人难以看懂。
vextq_f32例子如下。
float _a[] = {1,2,3,4}, _b[] = {5,6,7,8} ;
float32x4_t a = vld1q_f32(_a), b = vld1q_f32(_b);
float32x4_t r1 = vextq_f32(a,b,1); //r1={2,3,4,5}
float32x4_t r2 = vextq_f32(a,b,2); //r2={3,4,5,6}
float32x4_t r3 = vextq_f32(a,b,3); //r3={4,5,6,7}
ncnn中的使用例子如下
"prfm pldl1keep, [%4, #256] \n"
"ld1 {v9.4s, v10.4s}, [%4] \n"// v9 v10 = r10 r14
"ext v11.16b, v9.16b, v10.16b, #4 \n" //r11
Vd, Vn, Vm即3个通用的寄存器,它们的信息分别被encode在Rd, Rn, Rm中
根据arm文档所示,T只会是8b或者16b(这里的b表示byte,字节)
- T = 8b, when Q=0
- T = 16b, when Q=1
这个Q应该要同上文ld1进来时的Q相匹配。 因为前面ld1指令指定了v9,v10寄存器为4s,即4个32位。所以Q=1,即T只能为16b。
同时,index的信息被encode在imm4中(index基于字节表示偏移 index is the lowest numbered byte element to be extracted),
- imm4<2:0> when Q = 0, imm4<3> = 0
- imm4 when Q = 1, imm4<3> = x The encoding Q = 0, imm4<3> = 1 is reserved.
也就是说,当Q=0时,imm4只有3位是有效的(即index范围为0~7),即imm4<3>=0。Q=0,imm4<3>=1时无定义 当Q=1时,imm4的4位都有效,即index范围为0~15。
具体EXT实现的功能如下所示,下图每一格表示一个字节(8位),则其为64位,如果是Q=1时,则是16格
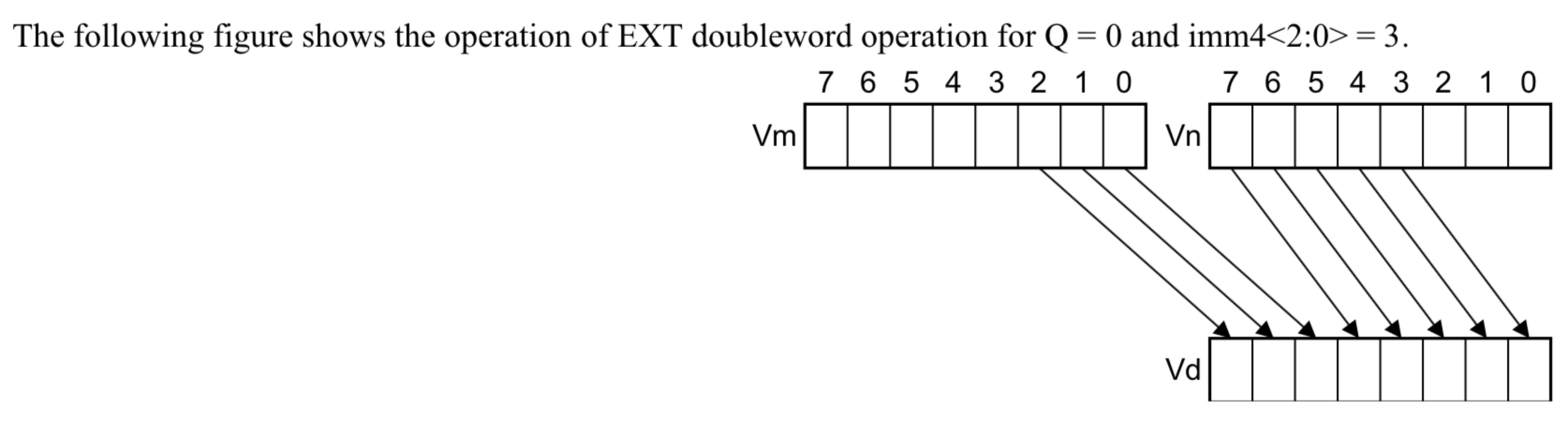
// Decode for this encoding
integer d = UInt(Rd); //Vd的位置被encode在Rd中
integer n = UInt(Rn); //同上
integer m = UInt(Rm); //同上
if Q == '0' && imm4<3> == '1' then UNDEFINED; //Q=0,imm4<3>=1时不存在
integer datasize = if Q == '1' then 128 else 64; //Q=1时用整个128位寄存器,Q=0用64位寄存器
integer position = UInt(imm4) << 3; //偏移的位用imm4x8,即字节转位
FMLA(by element)
Floating-point fused Multiply-Add to accumulator (by element).
FMLA(vector)
Floating-point fused Multiply-Add to accumulator (vector).
FMUL(vector)
Floating-point Multiply (vector).
以占位符方式访问向量寄存器
直接在后面加后缀来指明立场的;如浮点乘法的时候就是%16.4s指明是单精度浮点(4个single精度浮点值),同样的v21.s[3]是访问4个中的其中一个浮点值。(引自ncnn)
// v寄存器单路使用 %.s[0] %.s[1] %.s[2] %.s[3]
// a += b * c[0]
// a += b * c[1]
// a += b * c[2]
// a += b * c[3]
float32x4_t _a = vld1_f32(a);
float32x4_t _b = vld1_f32(b);
float32x4_t _c = vld1_f32(c);
asm volatile(
"fmla %0.4s, %2.4s, %3.s[0]"
"fmla %0.4s, %2.4s, %3.s[1]"
"fmla %0.4s, %2.4s, %3.s[2]"
"fmla %0.4s, %2.4s, %3.s[3]"
: "=w"(_a) // %0
: "0"(_a),
"w"(_b), // %2
"w"(_c) // %3
:
);